项目复盘(二)||innovation-LDA
项目复盘(二)||innovation-LDA
大创项目:基于Innovation-LDA的企业创新社区文本主题发现研究
时间:2019.11-2020.4
由于复试需要复盘我的项目,想在就简单梳理一遍
一、目的:
对小米社区的帖子进行分析,利用基于LDA原型算法改进的inno-LDA算法,提取帖子中的主题
二、输入和输出
- 数据来源:小米社区的数据 (不同时间段的)
- 爬虫:已经有的数据 有不同时间段的帖子 每份大概3w条
由于是老师提供的数据,都输出在excel里了,就没去仔细研究爬虫了
数据如图: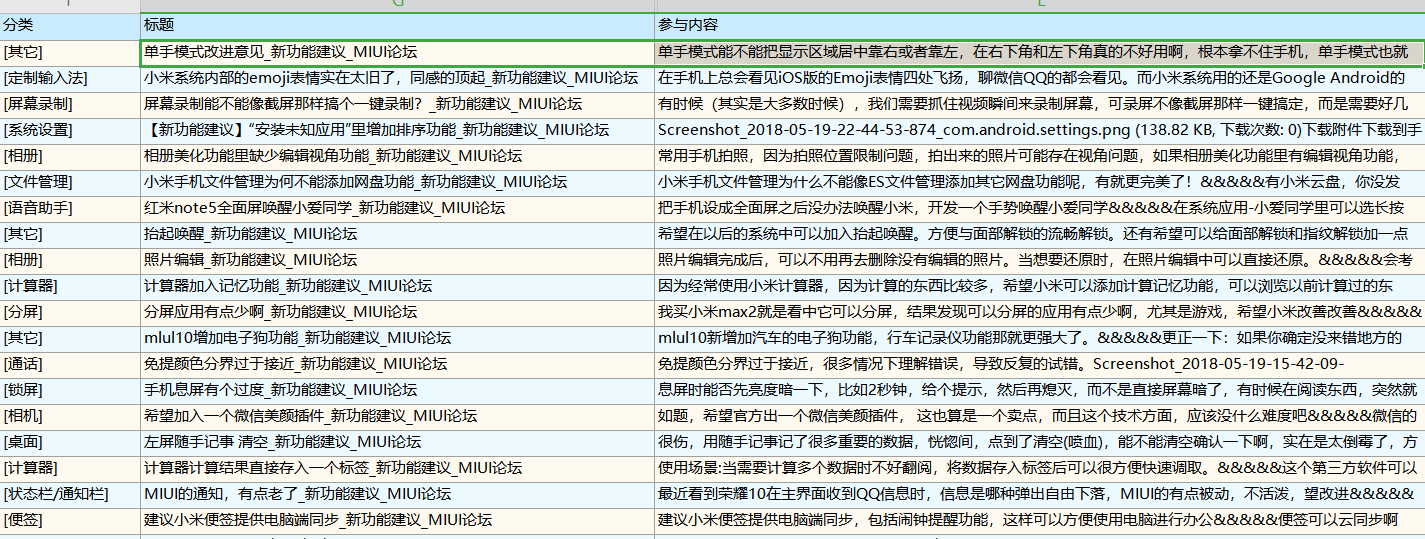
- 输出:每个算法程序的输出为每个帖子对应的主题
例如帖子1:
标题:单手模式改进意见_新功能建议_MIUI论坛
内容:单手模式能不能把显示区域居中靠右或者靠左...
输出为主题:单手模式
- 实现:我们实现的lda类模型有LDA,local_LDA,sent_LDA,inno_LDA四种。
我负责的是sent_lda。
三、方法和原理
LDA算法的原理:
Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2012, 3:993-1022.
吉布斯采样和EM变分算法的区别:
Inno-LDA的原理:
local_LDA的原理:
出自论文:Brody S, Elhadad N. An unsupervised aspect-sentiment model for online reviews
sent_lda算法的原理:
四、主要负责什么工作
Sent-lda的输入脚本开发
数据清洗,用正则表达式 比如繁体 字母大小写 特殊字符
正则表达式哪些比较好用?特殊
中文分词 用的是百度的jieba分词
自定义字典 对一些特定的专业词汇自定义分词
数据展示:困惑度整合成条形图,词云跑过主题图
Sent-lda算法的复现(这个没做)
lda主题算法和其他变形讲解?
五、遇到的问题如何解决
有些参数上的错误,造成算法错误
困惑度的计算
多线程跑,数据量大
我自己遇到的问题:一开始需要我复现输入脚本的代码,我就去读论文。但是似乎需要固定的格式作者没给出。就通读了下算法变形的地方,在我们复现的lda上做修改。不过最后找到原作者用到了他的脚本和软件。
感谢来自上交的鲍杨老师提供了脚本:
老师说要避免出现过拟合的现象
最后的结果是我们人工标记打分主题的匹配程度,inno-lda优于lda,但sentlda可能更好,具体原因就没再深究,我就结束了我的工作。家里有事加上考研。
我自己遇到的问题就是预处理,多个版本总是不一致
因为一开始就和原作者那个不一样,所以要修改原作者的脚本和我们的一致才行